Introdução
Loops são comuns na programação, mas podem ser lentos com conjuntos de dados grandes. O Pandas, usado para manipular dados em Python, oferece a função iterrows(). No entanto, para grandes conjuntos de dados, essa função é lenta. Vamos explorar maneiras mais rápidas de iterar em DataFrames do Pandas.
Criando Nosso Conjunto de Dados
Para mostrar as abordagens, criaremos um DataFrame com 5 milhões de linhas e 4 colunas, contendo números inteiros aleatórios de 0 a 50.
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 50, size=(5000000, 4)), columns=('a', 'b', 'c', 'd'))Alternativa 1: Iterrows
Vamos adicionar uma coluna ‘e’ ao DataFrame com as seguintes regras:
Se ‘a’ for 0, ‘e’ será igual a ‘d’.
Se ‘a’ estiver entre 1 e 25, ‘e’ será ‘b’ – ‘c’.
Caso contrário, ‘e’ será ‘b’ + ‘c’.
Vamos usar a função iterrows() para fazer isso.
import time
start = time.time()
for idx, row in df.iterrows():
if row.a == 0:
df.at[idx,'e'] = row.d
elif (row.a <= 25) & (row.a > 0):
df.at[idx,'e'] = (row.b) - (row.c)
else:
df.at[idx,'e'] = row.b + row.c
end = time.time()
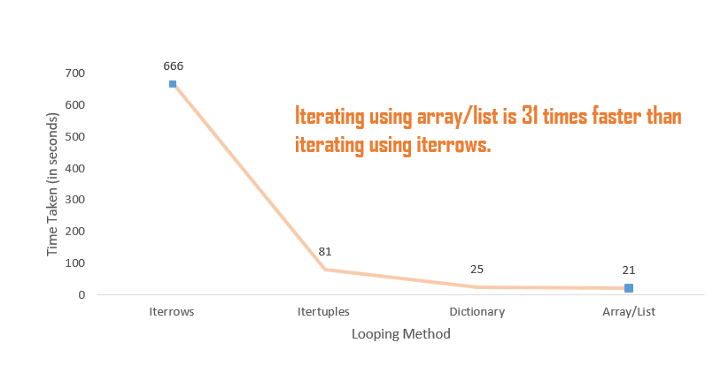
print("Tempo levado:", end - start)O uso do iterrows() leva cerca de 666 segundos (~11 minutos) para realizar as operações em 5 milhões de linhas.
Alternativa 2: Itertuples
Itertuples é uma alternativa para iterar sobre um DataFrame do Pandas. Ele itera sobre as linhas do DataFrame como tuplas nomeadas. Esta abordagem é mais eficiente do que iterrows.
start = time.time()
for row in df.itertuples():
if row.a == 0:
df.at[row.Index, 'e'] = row.d
elif (row.a <= 25) & (row.a > 0):
df.at[row.Index, 'e'] = (row.b) - (row.c)
else:
df.at[row.Index, 'e'] = row.b + row.c
end = time.time()
print("Tempo levado:", end - start)O uso de itertuples() leva cerca de 81 segundos, que é 8 vezes mais rápido que iterrows().
Alternativa 3: Dicionário
Outra alternativa é converter o DataFrame em um dicionário, realizar as operações no dicionário e, em seguida, converter o dicionário atualizado de volta em um DataFrame. Isso pode ser mais rápido do que iterrows() e itertuples().
start = time.time()
df_dict = df.to_dict('records')
for row in df_dict[:]:
if row['a'] == 0:
row['e'] = row['d']
elif row['a'] <= 25 & row['a'] > 0:
row['e'] = row['b'] - row['c']
else:
row['e'] = row['b'] + row['c']
df_result = pd.DataFrame(df_dict)
end = time.time()
print("Tempo levado:", end - start)Essa abordagem leva cerca de 25 segundos, o que é aproximadamente 3 vezes mais rápido do que itertuples().
Alternativa 4: Matriz/List
Essa abordagem é semelhante à alternativa do dicionário, mas usamos uma matriz em vez de um dicionário para fazer as operações.
start = time.time()
list2 = []
df['e'] = 0
for row in df.values:
if row[0] == 0:
row[4] = row[3]
elif row[0] <= 25 & row[0] > 0:
row[4] = row[1] - row[2]
else:
row[4] = row[1] + row[2]
list2.append(row)
df_result = pd.DataFrame(list2, columns=['a', 'b', 'c', 'd', 'e'])
end = time.time()
print("Tempo levado:", end - start)Essa abordagem leva cerca de 21 segundos, o que é cerca de 31 vezes mais rápida do que iterrows().
Conclusão
Para percorrer DataFrames de maneira mais eficiente, evite iterrows() e considere opções como itertuples(), dicionários ou matrizes/listas. Isso aumentará a velocidade das operações. Além disso, a vetorização é outra técnica útil para melhorar o desempenho em DataFrames