A análise de sentimento é uma técnica poderosa que ajuda computadores a compreender se um texto tem sentimento positivo ou negativo.
Neste guia você aprenderá a usar técnicas de Processamento de Linguagem Natural e Aprendizado de Máquina para determinar o sentimento de textos. Com o uso da biblioteca spaCy, criaremos um pipeline que alimenta um classificador de análise de sentimentos.
1. Teoria: Pré-processamento de Dados Textuais com PLN:
Pela teoria, antes de iniciarmos a construção do nosso analisador de sentimentos, é necessário preparar os dados textuais. Para isso, seguiremos algumas etapas de pré-processamento para garantir que os dados estejam em um formato adequado para análise.
Tokenização:
A tokenização envolve dividir um texto em unidades individuais chamadas tokens. Tokens podem ser palavras ou partes delas, como prefixos e sufixos. A tokenização é a base de muitos processos de PLN.
Exemplo de código em Python usando spaCy para tokenização:
import spacy
nlp = spacy.load("en_core_web_sm")
text = "Análise de sentimentos é interessante!"
doc = nlp(text)
tokens = [token.text for token in doc]
print(tokens)

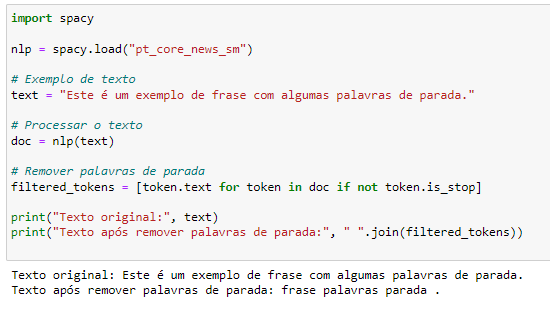
Remoção de Palavras de Parada:
Palavras como “e”, “o”, “para” não contribuem muito para a análise de sentimentos e podem ser removidas para melhorar o desempenho do modelo.
import spacy
nlp = spacy.load("pt_core_news_sm")
# Exemplo de texto
text = "Este é um exemplo de frase com algumas palavras de parada."
# Processar o texto
doc = nlp(text)
# Remover palavras de parada
filtered_tokens = [token.text for token in doc if not token.is_stop]
print("Texto original:", text)
print("Texto após remover palavras de parada:", " ".join(filtered_tokens))
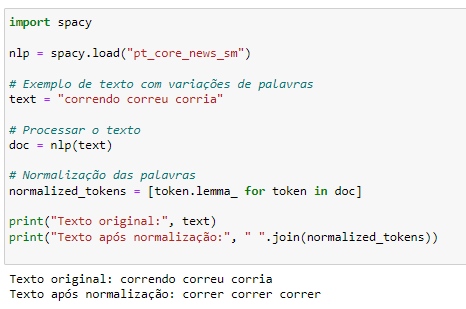
Normalização de Palavras:
Normalizar palavras significa reduzi-las a uma forma básica. Isso ajuda o modelo a generalizar melhor, reduzindo variações.
import spacy
nlp = spacy.load("pt_core_news_sm")
# Exemplo de texto com variações de palavras
text = "correndo correu corria"
# Processar o texto
doc = nlp(text)
# Normalização das palavras
normalized_tokens = [token.lemma_ for token in doc]
print("Texto original:", text)
print("Texto após normalização:", " ".join(normalized_tokens))
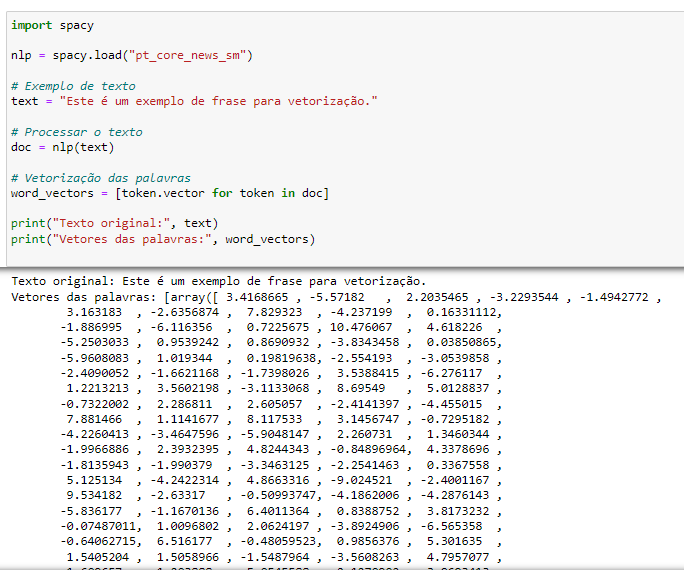
Vetorização de Texto:
Como os modelos de Aprendizado de Máquina não podem lidar diretamente com texto, precisamos convertê-lo em representações numéricas. Uma abordagem comum é a vetorização de texto.
import spacy
nlp = spacy.load("pt_core_news_sm")
# Exemplo de texto
text = "Este é um exemplo de frase para vetorização."
# Processar o texto
doc = nlp(text)
# Vetorização das palavras
word_vectors = [token.vector for token in doc]
print("Texto original:", text)
print("Vetores das palavras:", word_vectors)
2. Uso de Classificadores de Aprendizado de Máquina para Prever Sentimentos:
Agora que os dados estão pré-processados, podemos construir um classificador de Aprendizado de Máquina para prever sentimentos com base no texto.
Ferramentas de Aprendizado de Máquina:
Utilizaremos o spaCy, que já inclui um modelo pré-treinado para análise de sentimentos.
Como Funciona a Classificação:
A classificação envolve treinar um modelo em dados rotulados para associar entradas a rótulos. O modelo aprende padrões nos dados de treinamento e faz previsões sobre novos exemplos.
Como Usar spaCy para Classificação de Texto:
No spaCy, adicionamos um componente “textcat” ao pipeline. Esse componente é um classificador que treinamos para categorizar textos, como sentimentos positivos e negativos.
Exemplo de código para treinamento de classificador de sentimentos usando spaCy:
import spacy
from spacy.util import minibatch
import random
# Carregue o modelo de linguagem para o português do Brasil
nlp = spacy.load("pt_core_news_sm")
# Crie a tarefa de classificação de texto
textcat = nlp.create_pipe("textcat", config={"exclusive_classes": True})
textcat.add_label("positive")
textcat.add_label("negative")
nlp.add_pipe(textcat)
# Dados de treinamento
train_data = [
("Isso é ótimo!", {"cats": {"positive": 1, "negative": 0}}),
("Não estou feliz.", {"cats": {"positive": 0, "negative": 1}})
]
# Preparação dos dados para treinamento
train_texts, train_cats = zip(*train_data)
train_data = list(zip(train_texts, train_cats))
# Treinamento
random_seed = 1
spacy.util.fix_random_seed(random_seed)
train_data = train_data[:10] # Apenas para demonstração, use todos os dados
other_pipes = [pipe for pipe in nlp.pipe_names if pipe != "textcat"]
with nlp.disable_pipes(*other_pipes): # Desative outros componentes durante o treinamento
optimizer = nlp.begin_training()
for epoch in range(10):
random.shuffle(train_data)
losses = {}
# Crie minibatches e itere pelo conjunto de treinamento
for batch in minibatch(train_data, size=8):
texts, annotations = zip(*batch)
example_texts = list(texts) # Converta a tupla para lista
example_annotations = list(annotations) # Converta a tupla para lista
# Atualize o modelo com os exemplos do minibatch
nlp.update(example_texts, example_annotations, drop=0.5, losses=losses)
print(losses)
# Salve o modelo treinado
nlp.to_disk("trained_textcat_model_pt")
# Carregue o modelo treinado para português do Brasil
nlp = spacy.load("trained_textcat_model_pt")
# Textos para classificar
texts_to_classify = [
"Eu realmente gostei deste filme. A atuação foi ótima.",
"Esse produto não atendeu às minhas expectativas.",
"O atendimento ao cliente foi bom.",
"O clima hoje está lindo.",
]
# Classificação de texto
for text in texts_to_classify:
doc = nlp(text)
if "positive" in doc.cats and "negative" in doc.cats:
if doc.cats["positive"] < doc.cats["negative"]:
sentiment = "positivo"
else:
sentiment = "negativo"
print(f"Texto: '{text}'\nSentimento: {sentiment}\n")
else:
print(f"Texto: '{text}'\nNão foi possível classificar o sentimento.\n")

Conclusão e Próximos Passos:
A análise de sentimentos é uma aplicação valiosa do PLN com várias aplicações práticas. Com o spaCy e outras bibliotecas de Aprendizado de Máquina em Python, você pode criar analisadores de sentimentos eficazes para compreender os tons emocionais nos textos.
Esse guia fornece uma visão geral do processo de construção de um analisador de sentimentos. No entanto, há muitas oportunidades para aprimoramento, como ajustar parâmetros, experimentar diferentes algoritmos de Aprendizado de Máquina e explorar fontes mais diversas de dados para treinamento.